
Introduction to RAG and Evaluation Importance
Understanding Retrieval Augmented Generation (RAG)
Retrieval Augmented Generation, commonly known as RAG, represents a significant advancement in the field of artificial intelligence, particularly in enhancing the capabilities of large language models (LLMs) such as ChatGPT. This innovative approach combines the power of LLMs with external knowledge sources, resulting in more accurate and contextually relevant responses.
At its core, a RAG system integrates three key components:
- A sophisticated large language model
- A robust vector database for efficient information retrieval
- Carefully crafted prompts that guide the interaction between the LLM and the retrieved information
This synergy allows RAG systems to tap into vast repositories of up-to-date information, significantly reducing the likelihood of generating inaccurate or outdated responses, a common challenge with standalone LLMs.
The Critical Need for RAG Evaluation
As the adoption of RAG technologies accelerates across various industries, the importance of rigorous evaluation methodologies becomes increasingly apparent. Effective evaluation of RAG applications goes beyond simple comparisons; it demands a comprehensive approach using quantifiable, reproducible, and convincing metrics.
The significance of thorough RAG evaluation cannot be overstated:
- It ensures the precision and dependability of AI-generated content
- It plays a crucial role in minimizing factual inconsistencies and hallucinations
- It enables the fine-tuning and optimization of various RAG system components
- It builds and maintains user trust in AI applications
As we navigate the rapidly evolving landscape of AI, consistent evaluation and refinement of RAG applications are essential for maintaining their reliability and effectiveness.
RAG Evaluation Metrics
To comprehensively assess RAG applications, we’ll explore three distinct categories of evaluation metrics:
- Metrics leveraging ground truth data
- Metrics applicable without ground truth
- Metrics based on analysing LLM responses
Metrics Based on Ground Truth
In the context of RAG evaluation, ground truth refers to a set of predefined, verified answers or relevant document segments corresponding to specific user queries. These serve as a benchmark against which we can measure the performance of RAG systems.
When ground truth consists of complete answers, we can employ metrics such as semantic similarity and answer correctness to directly compare RAG-generated responses with the established ground truth.
Below is an example of evaluating answers based on their correctness:
Ground truth: Marie Curie was born in 1867 in Poland. High answer correctness: In 1867, in Poland, Marie Curie was born. Low answer correctness: In France, Marie Curie was born in 1867.
In cases where ground truth is represented by document chunks, the evaluation focuses on the retrieval aspect of RAG systems. Here, we utilize metrics like Exact Match (EM), Rouge-L, and F1 scores to gauge how effectively the system retrieves and utilizes relevant information from its knowledge base.
Generating Ground Truth for Custom Datasets
For scenarios involving proprietary or specialized datasets, creating ground truth can be challenging. One effective approach is to leverage advanced language models like ChatGPT to generate sample questions and answers based on your specific dataset. Additionally, tools such as Ragas and LlamaIndex offer functionalities to create test data tailored to your unique knowledge base.
Metrics Without Ground Truth
Evaluating RAG applications in the absence of ground truth presents unique challenges, but innovative solutions have emerged to address this need. One notable approach is the RAG Triad concept, introduced by the open-source evaluation tool TruLens-Eval.
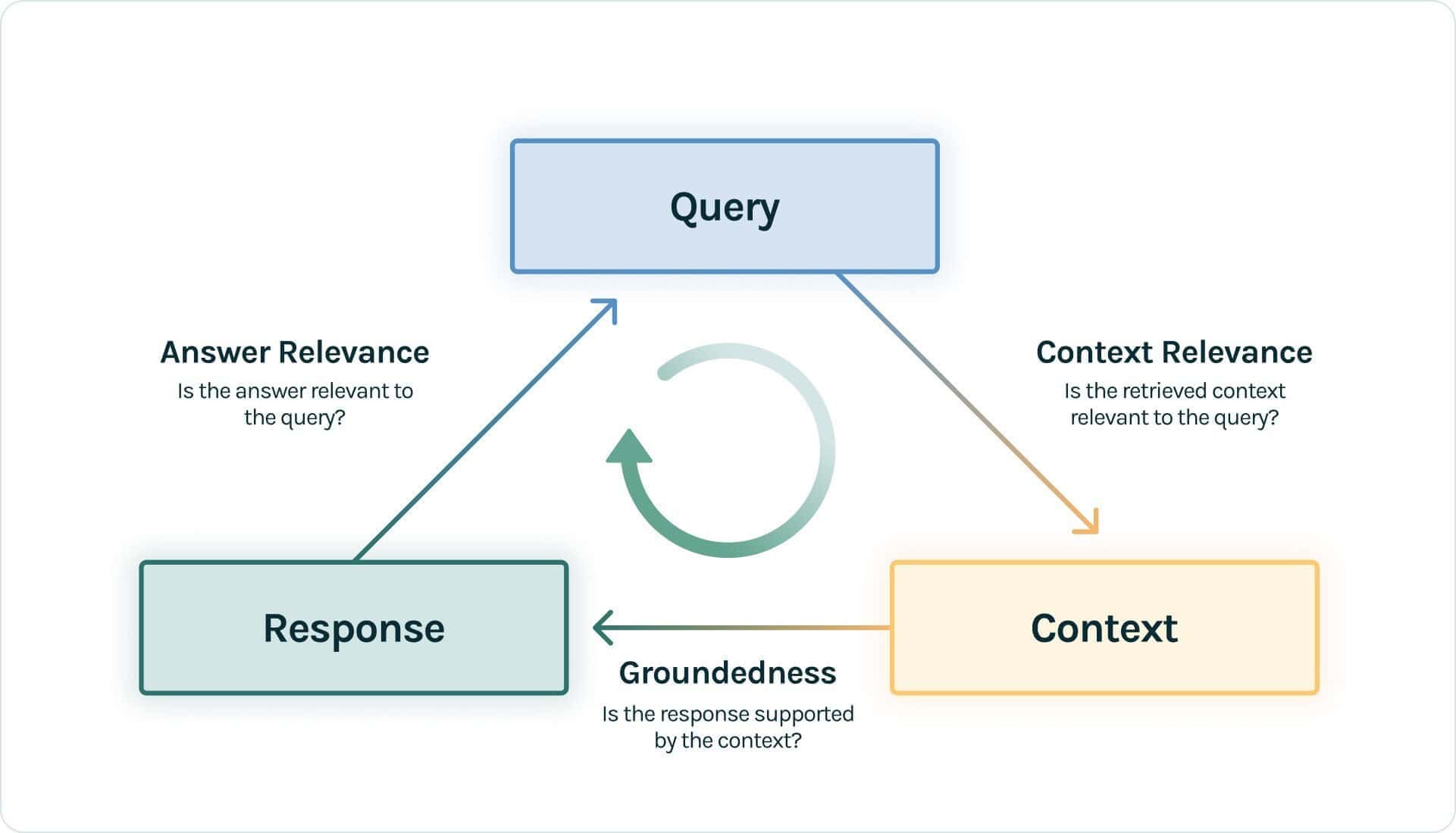
The RAG Triad focuses on assessing the interrelationships between the query, the retrieved context, and the generated response. It comprises three key metrics:
- Context Relevance: This metric evaluates how well the retrieved information aligns with and supports the initial query.
- Groundedness: It measures the extent to which the LLM’s response is rooted in and justified by the retrieved context.
- Answer Relevance: This assesses how directly and appropriately the final response addresses the original query.
Below is an example of evaluating answers based on their relevance to the question:
Question: Where is Japan and what is its capital? Low relevance answer: Japan is in East Asia. High relevance answer: Japan is in East Asia and Tokyo is its capital.
Metrics Based on LLM Responses
The third category of evaluation metrics focuses on analyzing the qualitative aspects of LLM-generated responses. These metrics go beyond factual accuracy to assess various dimensions of the output’s quality and appropriateness.
Some key aspects evaluated by these metrics include:
- Friendliness: How approachable and user-friendly is the response?
- Potential for harm: Does the response contain any content that could be considered harmful or inappropriate?
- Conciseness: How efficiently does the response convey the necessary information?
Frameworks like LangChain have proposed an extensive set of such metrics, including but not limited to:
- Relevance: How well does the response address the query?
- Coherence: Is the response logically structured and easy to follow?
- Helpfulness: Does the response provide valuable information or assistance?
- Controversiality: Does the response touch on sensitive or divisive topics?
- Bias: Does the response show any unintended biases?
Below is an example of evaluating answers based on their conciseness:
Question: What’s the chemical formula for water? Low conciseness answer: The chemical formula for water? Well, that’s a fundamental question in chemistry. The answer you’re looking for is that water consists of two hydrogen atoms and one oxygen atom, which is represented as H2O. High conciseness answer: H2O
Advanced Evaluation Techniques
Using LLMs to Score Metrics
The process of scoring RAG outputs against various metrics can be complex and time-consuming. However, recent advancements in LLM capabilities have opened up new possibilities for streamlining this process. By leveraging models like GPT-4, we can now automate much of the evaluation process through carefully designed prompts.
This approach involves creating a prompt that instructs the LLM to act as an impartial judge, evaluating the quality of RAG-generated responses based on specific criteria. The LLM then provides both a qualitative assessment and a numerical score, offering a comprehensive evaluation of the response.
To mitigate potential issues, consider employing advanced prompt engineering techniques such as:
- Multi-shot learning: Providing multiple examples to guide the LLM’s understanding of the task
- Chain-of-Thought (CoT) prompting: Encouraging the LLM to show its reasoning process, leading to more transparent and potentially more accurate evaluations
The paper “Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena” proposes a prompt design for GPT-4 to judge the quality of an AI assistant’s response:
[System]
Please act as an impartial judge and evaluate the quality of the response
provided by an AI assistant to the user question displayed below. Your
evaluation should consider factors such as the helpfulness, relevance,
accuracy, depth, creativity, and level of detail of the response. Begin
your evaluation by providing a short explanation. Be as objective as
possible. After providing your explanation, please rate the response on
a scale of 1 to 10 by strictly following this format: "[[rating]]",
for example: "Rating: [[5]]".
[Question]
{question}
[The Start of Assistant's Answer]
{answer}
[The End of Assistant's Answer]It is important to note that GPT-4, like any judge, is not infallible and might have biases and potential errors. So, prompt design is crucial.
Hallucination Detection and Factual Consistency
A critical challenge in RAG systems is ensuring the factual consistency of generated responses and minimizing hallucinations — instances where the system produces information not grounded in the provided context. Addressing this challenge, Vectara has developed the Hughes Hallucination Evaluation Model (HHEM), now in its second version.
HHEM v2 represents a significant advancement in hallucination detection and factual consistency scoring. Its key features include:
- Multilingual Capability: HHEM v2 can evaluate content in English, German, and French, with plans to expand to more languages.
- Extensive Context Handling: The model can process large volumes of text, making it particularly suitable for RAG applications.
- Calibrated Scoring: HHEM v2 provides scores that have a direct probabilistic interpretation. For instance, a score of 0.8 indicates an 80% likelihood that the evaluated text is factually consistent with its source.
| Model | AggreFact-SOTA (Balanced accuracy) | RAGTruth-Summarization (Precision) | RAGTruth-Summarization (Recall) |
|---|---|---|---|
| HHEM v2 | 73% | 81.48% | 10.78% |
| GPT-3.5 | 56.3% — 62.7% | 100% | 1.00% |
| GPT-4 | 80% | 46.9% | 82.2% |
RAG Evaluation Tools and Frameworks
Now that we have covered evaluating a RAG application, let’s explore some tools for assessing RAG applications.
Overview of Evaluation Tools
| Tool | Key Features | Best Use Case |
|---|---|---|
| Ragas | Open-source, flexible metrics, no framework requirements | General RAG evaluation |
| LlamaIndex | Integrated with LlamaIndex framework, easy setup | Evaluating LlamaIndex-based RAG apps |
| TruLens-Eval | Supports LangChain and LlamaIndex, visual monitoring | Detailed evaluation with GUI |
| Phoenix | Complete set of LLM metrics, including embedding quality | Comprehensive LLM and RAG evaluation |
Deep Dive: Ragas for RAG Evaluation
Ragas is an open-source evaluation tool for assessing RAG applications. With a simple interface, Ragas streamlines the evaluation process. Here’s how to use Ragas:
from ragas import evaluate
from datasets import Dataset
dataset: Dataset
results = evaluate(dataset)
# {'ragas_score': 0.860, 'context_precision': 0.817,
# 'faithfulness': 0.892, 'answer_relevancy': 0.874}Integrating Evaluation with Vectara
To demonstrate how to integrate evaluation with a RAG service like Vectara, let’s look at an example using RAGAs:
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from ragas.metrics import (
faithfulness, answer_relevancy,
answer_similarity, answer_correctness
)
def eval_rag(df):
df2 = df.copy()
df2[['answer', 'contexts']] = df2.apply(get_response, axis=1)
result = evaluate(
Dataset.from_pandas(df2),
metrics=[
faithfulness, answer_relevancy,
answer_similarity, answer_correctness
],
llm=ChatOpenAI(
model_name="gpt-4-turbo-preview",
temperature=0
),
raise_exceptions=False
)
return resultPractical Considerations and Best Practices
Generating Evaluation Datasets
One of the challenges in RAG evaluation is obtaining or creating appropriate datasets. Here are some methods to address this challenge:
- Using existing benchmarks: Datasets like AggreFact and RAGTruth can be used for general evaluation.
- Synthetic data generation: Tools like RAGAs offer capabilities to generate synthetic question-answer pairs based on your corpus.
- Manual curation: Create a set of questions and answers specific to your domain or use case.
Here’s an example of synthetic data generation using RAGAs:
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
gen_llm = ChatOpenAI(model="gpt-3.5-turbo")
critic_llm = ChatOpenAI(model="gpt-4-turbo-preview")
emb = OpenAIEmbeddings(model="text-embedding-3-large")
generator = TestsetGenerator.from_langchain(
generator_llm=gen_llm,
critic_llm=critic_llm,
embeddings=emb
)
testset = generator.generate_with_langchain_docs(
documents,
test_size=n_questions,
raise_exceptions=False,
with_debugging_logs=False,
distributions={
simple: 0.5,
reasoning: 0.2,
multi_context: 0.3
}
)Optimizing RAG Performance
Once you have your evaluation metrics in place, the next step is to use these insights to optimize your RAG system’s performance.
| Run | Lambda | MMR | Prompt | Faithfulness | Answer Relevancy | Answer Similarity | Answer Correctness |
|---|---|---|---|---|---|---|---|
| 1 | 0 | True | Basic | 0.9772 | 0.9427 | 0.9422 | 0.5045 |
| 2 | 0 | False | Basic | 0.9580 | 0.9395 | 0.9436 | 0.5135 |
| 3 | 0.025 | False | Basic | 0.9493 | 0.9469 | 0.9487 | 0.5640 |
| 4 | 0.025 | False | Advanced | 0.9744 | 0.9200 | 0.9550 | 0.5941 |
Key takeaways for optimization:
- Experiment with different retrieval parameters (e.g., lambda, MMR)
- Test various prompts or LLM configurations
- Monitor multiple metrics to ensure overall improvement
- Consider the trade-offs between different metrics (e.g., faithfulness vs. answer relevancy)
Future Trends in RAG Evaluation
Emerging Challenges and Solutions
As RAG systems continue to evolve, so too must our evaluation methodologies. Here are some emerging trends and challenges in RAG evaluation:
- Multi-modal RAG: As RAG systems begin to incorporate images, audio, and video, evaluation metrics will need to adapt to assess these multi-modal outputs.
- Evaluation of reasoning capabilities: Future RAG systems may incorporate more complex reasoning. Metrics to evaluate the quality and correctness of this reasoning will be crucial.
- Real-time evaluation: As RAG systems are deployed in production environments, there’s a growing need for real-time evaluation and monitoring.
- Bias and fairness: Ensuring that RAG systems are unbiased and fair across different demographics and topics will be an important area of focus.
- Efficiency metrics: As the scale of RAG systems grows, metrics that evaluate the efficiency of retrieval and generation will become more important.
To address these challenges, we can expect to see:
- Development of new, more sophisticated evaluation metrics
- Increased use of synthetic data for evaluation
- More robust benchmarks that cover a wider range of use cases and data types
- Integration of evaluation tools directly into RAG frameworks for easier monitoring and optimization
Conclusion
Evaluating RAG applications is a critical step in developing reliable and effective AI systems. By using a combination of ground truth-based metrics, metrics without ground truth, and LLM-based evaluations, we can gain a comprehensive understanding of our RAG system’s performance.
Tools like Ragas, LlamaIndex, TruLens-Eval, and Phoenix provide powerful capabilities for implementing these evaluations. Moreover, advanced techniques like Vectara’s HHEM v2 offer promising approaches to tackling challenging problems like hallucination detection.
In the fast-changing world of AI, regularly evaluating and enhancing RAG applications is crucial for their reliability. The methodologies, metrics, and tools discussed here provide a solid foundation for developers and businesses to make informed decisions about the performance and capabilities of their RAG systems, driving the progress of AI applications.


