
Modern RAG systems have come a long way from their early forms. These RAG systems now use advanced techniques to solve complex information retrieval problems. HtmlRAG, for instance, uses the original HTML structure to make sure the most relevant data is found. Meanwhile, the multimodal RAG approach integrates diverse data types, improving performance over standard RAG models. The secret sauce? Combining text with visual data, as seen in multimodal RAG. On the other hand, agentic RAG systems bring a new level of autonomy. They refine searches and adapt queries, enhancing retrieval accuracy. Curious how agentic RAG works? It critiques retrieval quality and retries for better results. These innovations redefine RAG systems, unlocking untapped potential in information retrieval.
Key Takeaways
- Agentic RAG improves search accuracy by changing queries and refining searches.
- Multimodal RAG uses both text and image data, outperforming standard models.
- HtmlRAG uses the HTML structure to keep documents intact and relevant.
- Traditional RAG struggles with data quality and query-retrieval mismatches.
- Future RAG systems will overcome these limitations and advance AI capabilities.
Understanding Traditional RAG Systems
Let’s look at how basic RAG systems work to understand how they’ve evolved. Traditional RAG systems use a retrieval mechanism alongside generative AI to improve the accuracy of responses. They focus on core components, typical ways they’re set up, and common use cases.
Traditional RAG systems depend heavily on how documents are processed and retrieved. They find documents to give context to AI-generated responses, which sometimes leads to errors. These systems integrate with language models to find a balance between precision and the scope of information.
Key components include finding, processing, and combining documents. Retrieval mechanisms use indexing and search algorithms, while processing involves parsing and extracting context. These are the basic elements of traditional RAG systems that have paved the way for modern advancements.
Traditional RAG systems often involve simple document searches, using keyword matching or semantic analysis. But these methods don’t always deliver the desired level of detail, especially in specialized areas. This is where modern systems like multimodal RAG and agentic RAG come into play.
Multimodal RAG improves performance by using text and images to create a richer data context. It bridges the gap between simple text-based systems and the varied nature of real-world data. Agentic RAG refines search queries and retrieval processes, addressing limitations by checking and improving retrieval quality through iteration.
Performance metrics such as retrieval speed and accuracy are key for evaluating RAG systems. Ensuring high-quality data retrieval and synthesis remains a top priority. Despite their challenges, traditional RAG systems have set the stage for more advanced solutions.
| Core Components | Retrieval Mechanisms | Implementation Patterns | Common Scenarios |
|---|---|---|---|
| Document Processing | Keyword Matching | Basic Document Search | Customer Support |
| Language Model Integration | Semantic Analysis | Indexing | Knowledge Bases |
| Data Parsing | Search Algorithms | Semantic Retrieval | Virtual Assistants |
| Query-Response Generation | Indexed Data Access | Direct Query Matching | FAQ Systems |
| Performance Metrics | Fast Retrieval | Real-Time Processing | Content Management Systems |
Limitations of Standard RAG Approaches
When we look at the limitations of typical RAG methods, we see that they depend heavily on the quality of the documents they retrieve. This can cause several issues across different types of RAG systems. Let’s explore these limitations:
-
Document Structure Preservation: Traditional methods often struggle to keep the original structure when retrieving different formats like HTML. This loss of the HTML structure reduces the quality of the response.
-
Context Loss During Retrieval: There’s a high chance of losing context, especially in complex documents. Standard methods might retrieve data that, while relevant on its own, doesn’t fully connect with what the user is asking.
-
Handling of Complex Document Formats: Dealing with complex formats like HTML or XML is very challenging. These formats often have nested structures that standard systems can’t easily understand.
-
Multimodal Content Limitations: Combining different types of content like text and images is difficult. This problem directly affects multimodal RAG performance, where integrating data types is key for comprehensive responses.
-
Query Understanding Challenges: Traditional systems sometimes misunderstand what the user is asking. This leads to inaccurate results, reducing the effectiveness of agentic RAG searches.
-
Scalability and Performance Issues: Large datasets increase the time it takes to get results, making real-time processing hard. This scalability issue limits the ability of systems to perform retrieval-augmented generation efficiently.
-
Resource Intensity and Computational Costs: These systems need a lot of computing power, which can be expensive. Balancing the use of resources with performance is a key challenge for developers.
-
Integration Complexity: Integrating these systems with existing setups can be tricky. It often requires customized solutions, which can complicate how things work.
These limitations led to the development of agentic RAG and other advanced systems. By addressing these problems, modern RAG variants like multimodal RAG and agentic RAG address these issues effectively, making sure newer systems perform better than older ones in different situations.
Exploring HtmlRAG and Its Features

Looking at the features of HtmlRAG shows how it uses a unique approach to document retrieval. By using the structure of HTML, HtmlRAG keeps the organization of documents intact. This is a big change from text-only methods, ensuring that context is preserved during retrieval.
HtmlRAG is different because it has moved from simple text-based retrieval to a system that understands structure. This change means that the quality of information and retention of context are greatly improved. Compared to traditional document processing, HtmlRAG offers clear advantages, especially where keeping document structure is crucial.
To use HtmlRAG, you need to consider certain things, such as its impact on performance and potential trade-offs. For example, while HtmlRAG can improve document retrieval, it may need more computing resources and effort to set up. Developers need to carefully consider these aspects to fully utilize its capabilities.
Interestingly, HtmlRAG has created new business opportunities because of its ability to maintain data integrity. Companies are using it to improve content management systems and digital libraries, where document hierarchy is very important. The need for systems that can handle complex document structures without losing data has never been greater.
Compared to standard retrieval methods, which might fail, HtmlRAG excels at keeping essential document elements. This makes sure that the retrieved information is both relevant and accurate, reducing common problems with query mismatches.
As industries need more advanced retrieval methods, HtmlRAG is setting a new standard. It works well with other advanced systems like agentic RAG and multimodal RAG, which also improve data retrieval. The combination of these modern techniques shows how far retrieval-augmented generation has progressed.
In short, HtmlRAG is more than just a tool; it’s a new way of thinking. By focusing on structure and context, it changes how we interact with large amounts of digital information.
Core Principles of HtmlRAG
Looking at the basic concepts of HtmlRAG reveals its unique strengths. HtmlRAG focuses on keeping the integrity of document structure while improving retrieval efficiency. Keeping this structure is key because it allows for a more accurate representation of documents. This is different from standard RAG systems, which often ignore document details.
-
Structure Preservation: HtmlRAG’s ability to maintain the document’s organization makes it unique. This ensures context is consistent, which is crucial for accurate data representation.
-
HTML Processing: The system is good at understanding and keeping HTML details. This is a big advantage for tasks that need precise document comprehension.
-
Document Hierarchy Management: HtmlRAG manages the different levels of a document effectively, making sure that context is never lost during retrieval.
-
Context Retention: By keeping the original context, HtmlRAG reduces errors common in query mismatches, making it a reliable choice.
-
Processing Pipeline Overview: The system’s processing pipeline efficiently handles HTML data, improving data speed without sacrificing quality.
-
Integration with LLM Systems: HtmlRAG’s easy integration with Large Language Models (LLMs) boosts its retrieval capabilities. This combination supports complex queries easily.
-
Performance Optimization: Thanks to its advanced algorithms, HtmlRAG is fast and accurate, which is essential for handling large datasets.
In addition to HtmlRAG, efforts to create multimodal RAG systems have been essential. These systems enhance performance by combining text and image data, improving data retrieval. Similarly, agentic RAG systems tackle the challenge of refining queries. They adaptively change queries, ensuring that retrieval tasks align closely with user needs. Each approach contributes to a more robust data retrieval system.
HtmlRAG Structure and Functionality
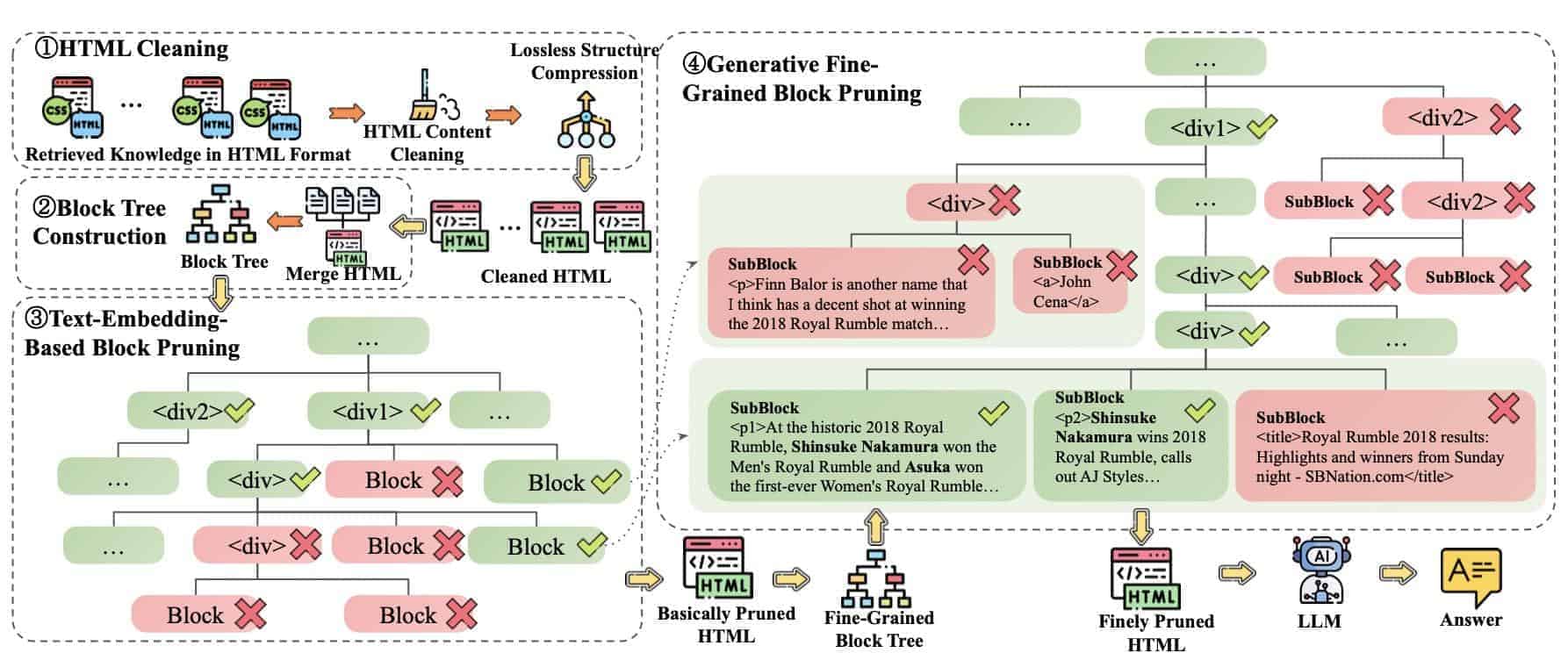
The design and operations of HtmlRAG provide insights into how it works. HtmlRAG’s technical setup effectively manages and processes structured HTML content, ensuring smooth content retrieval. By focusing on the architectural components, it uses HTML’s structure to ensure data integrity.
Each component plays a key role, from refining HTML elements to improving retrieval efficiency. This includes HTML cleaning, where unnecessary tags are removed to simplify the structure. Pruning methods further improve this by focusing on essential sections using a block tree approach. The result is a system that adapts to user queries with greater accuracy while keeping critical content.
As data moves through HtmlRAG, its processing stages keep the document’s original structure. This is crucial for maintaining the document’s integrity and relevance to queries. Query processing adaptations are used to boost search relevance and retrieval efficiency, generating more accurate responses.
Integration with existing systems is easy, promoting a smooth flow of data and retrieval. Performance strategies are then used to ensure fast and accurate data delivery. A focus on response generation makes sure that the information is not just retrieved but also presented clearly.
| Component | Function | Relevance | Keyword |
|---|---|---|---|
| HTML Cleaning | Simplifies structure, removes unnecessary tags | High | Standard RAG |
| HTML Pruning | Retains essential parts | Medium | Types of RAG systems |
| Query Processing | Enhances search relevance | High | RAG Work |
| Response Generation | Ensures coherent information delivery | High | Agentic RAG |
| System Integration | Promotes seamless data flow | Medium | Multimodal RAG |
HtmlRAG’s detailed yet efficient structure marks a significant advancement in retrieval systems. By addressing traditional limitations, it sets a new standard in handling HTML data.
Techniques for HTML Cleaning
Cleaning HTML content for better retrieval involves several methods. These help prepare HTML documents by keeping their core structure and removing unneeded parts. This makes sure that essential data is retained for efficient retrieval.
-
HTML cleaning workflow steps: Start by identifying unnecessary tags and attributes. Removing these can streamline content without losing relevant information.
-
Tag management strategies: Use rules for tag retention and removal to optimize HTML files. This helps keep the document’s integrity.
-
Content prioritization methods: Focus on what is needed for retrieval. Prioritize sections of text or code that meet the retrieval criteria, discarding irrelevant portions.
-
Structure simplification approaches: Simplify the document layout for better processing. This could include collapsing nested structures that don’t help with data retrieval.
-
Performance impact considerations: Assess how HTML cleaning affects retrieval speed and efficiency. The goal is to improve performance without reducing data quality.
-
Common challenges and solutions: One common issue is balancing the removal of unnecessary data and keeping essential information. Developing a strong set of rules can help with this.
-
Best practices and guidelines: Use best practices for consistent HTML cleaning results. Regular reviews and updates to these guidelines can make sure they remain effective.
These techniques are crucial for optimizing HTML files, especially when using modern RAG systems. By ensuring that the HTML is clean and organized, retrieval processes become more effective and less prone to errors.
Methods for HTML Pruning
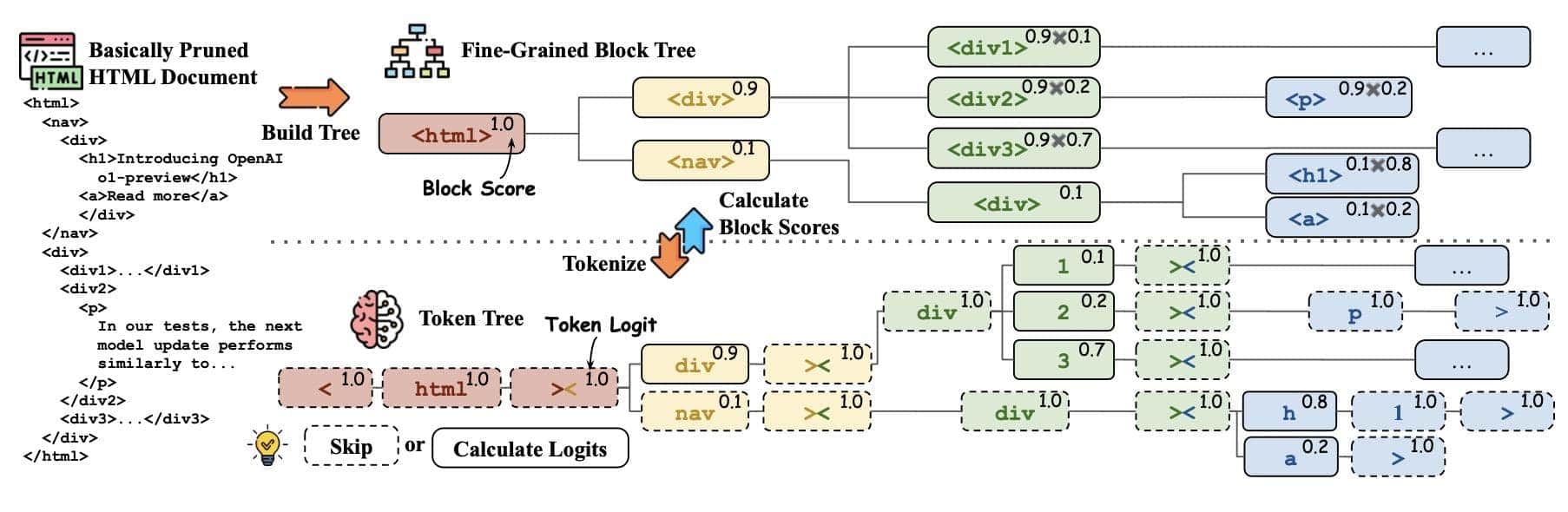
Pruning methods focus on optimizing HTML content through targeted reduction. These techniques refine the data by using pruning algorithms. These algorithms carefully evaluate each HTML block for relevance. They consider user queries, prioritizing essential content while removing the unnecessary. This balance between document size and information integrity ensures that important content is kept.
Performance optimization becomes crucial at this stage. Imagine trying to find a needle in a haystack; effective pruning reduces the haystack. It improves retrieval quality by removing irrelevant data, making the document lean and efficient.
Practical implementation needs careful consideration of various factors. The decision criteria for what to keep and what to remove should be precise. Each decision affects retrieval speed and accuracy. A well-pruned HTML document not only speeds up retrieval but also makes sure that the information retrieved is relevant to the context.
Real-world applications show the benefits of good pruning. From faster page load times to improved search results, the effects are clear. In situations where multimodal retrieval is involved, pruning ensures text works well with visual data, improving overall performance.
In advanced systems, agentic processes refine retrieval further by changing queries based on initial results. They adapt, learning from previous interactions to improve future outcomes. This adaptability is key for handling various data types like HTML and multimedia.
Introduction to Multimodal RAG

The evolution of retrieval systems has seen interesting advancements, especially in handling different types of content. Multimodal Retrieval-Augmented Generation (RAG) is a groundbreaking approach that includes different content types, bridging the gap between text and visual information. This goes beyond the limitations of text-only systems by using images and other media in the retrieval process. It’s like a system that speaks multiple languages, understanding the details of both text and imagery.
Using different modalities enhances performance and accuracy, creating a more complete understanding of the data it processes. It’s like giving a detective both the crime scene photo and the suspect’s statement; the more information, the better the deduction. The processing pipeline for these systems is advanced yet efficient, allowing smooth transitions between different data types. This is key for real-time applications, where time is crucial.
Multimodal RAG systems are effective in areas like digital marketing, healthcare, and entertainment. Imagine an AI that can analyze a medical image and compare it with patient records to help with diagnosis. Such capabilities show the potential for better decision-making and user experience. But it’s not always easy; implementing these systems requires careful consideration of the technology and data management.
Performance is very important. The system’s ability to handle large datasets and complex queries is essential. This is where things get real — making sure the retrieval process is both fast and accurate. Future development is focusing on more advanced integrations, possibly including real-time video analysis or advanced image recognition.
As these systems continue to evolve, the potential applications expand, presenting exciting opportunities for their use. It’s not just about using more data types; it’s about creating a cohesive, intelligent system that uses all available information to provide the best results.
Key Concepts in Multimodal RAG
Looking at the core principles of Multimodal RAG involves understanding how these systems combine different content types while keeping relevance and context.
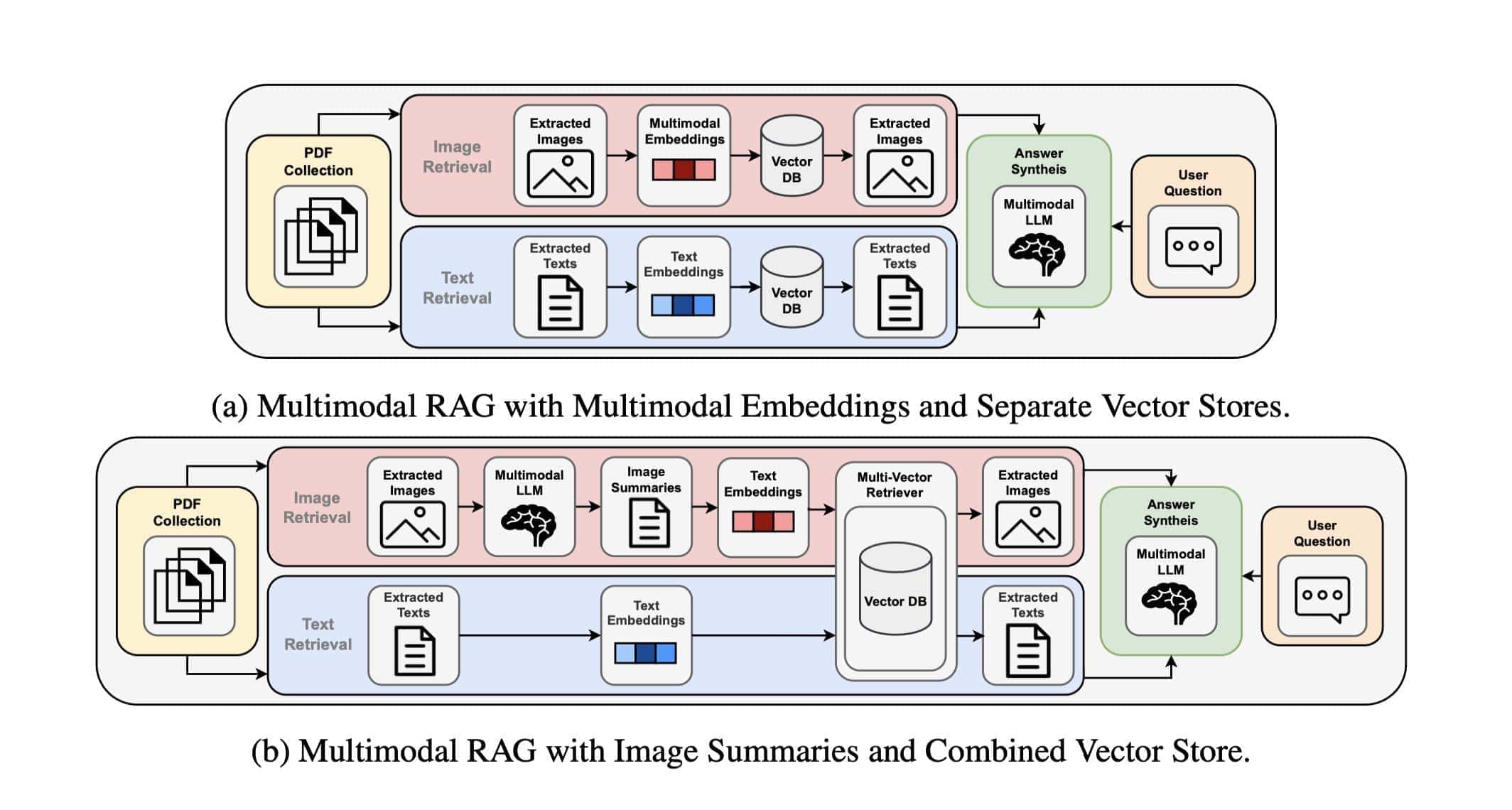 The process starts with unified embedding strategies, allowing text and image data to exist together smoothly. These embeddings don’t just compress data but ensure that each piece contributes to a clear response.
The process starts with unified embedding strategies, allowing text and image data to exist together smoothly. These embeddings don’t just compress data but ensure that each piece contributes to a clear response.
Handling cross-modal relationships is also crucial. It’s not enough to just put text with images; there needs to be a meaningful connection. This means understanding how different content types can complement each other, enhancing the overall system’s effectiveness.
Content type processing specifics look at how each data type is treated. Whether it’s images or text, each type needs a different approach to ensure nothing is missed. Vector space considerations are important here, ensuring that all data is in a common framework that allows for efficient retrieval.
Relevance scoring methods are key to getting high-quality results. This process ranks the embedded data, making sure that the most important information comes first. Meanwhile, context preservation techniques ensure that the retrieved data keeps its original meaning, avoiding mismatches.
Finally, integration challenges and solutions address the difficulties of combining these different data types into a cohesive system. It’s like putting together a puzzle, where every piece must fit perfectly. Solutions often involve innovative coding techniques or using existing frameworks for better performance.
Performance Analysis of Multimodal RAG Systems
Evaluating the performance of Multimodal RAG systems involves a deep look at specific metrics and methods. Testing methods focus on precision, recall, and response time to get a full picture of system performance. These metrics help identify areas where these systems excel and where they need improvement.
Cross-modal accuracy is a critical metric for evaluating Multimodal RAG systems. This measures how well the system can relate and retrieve information across different modalities. High cross-modal accuracy means the system can find relevant images when given a text query and vice versa.
Benchmarks for performance offer a structured way to compare different systems, providing industry standards that serve as points of reference. Optimization strategies focus on fine-tuning these systems, balancing accuracy with speed for the best user experience.
Resource requirements are also important. Multimodal RAG systems can be resource-intensive, requiring significant computational power. Scalability is a key consideration — the system needs to maintain performance even as data volumes grow.
Comparative studies often show how multimodal approaches outperform text-only systems in scenarios where visual information adds significant context. These findings help define the strengths and areas for improvement in these systems.
Deep Dive into Agentic RAG

Taking a closer look at agentic retrieval-augmented generation systems reveals a sophisticated approach to data retrieval. These systems bring a new level of autonomy, refining searches and adapting queries to enhance retrieval accuracy.
Core Architecture of Agentic RAG
The architecture of agentic RAG systems is built on the principles of intelligent agents. These agents operate autonomously, making decisions about how to refine queries and improve retrieval results.
The agent-based architecture introduces a layer of decision-making that traditional RAG systems lack. This includes query planning, where the system strategically decides how to approach a complex information need, and retrieval orchestration, where multiple retrieval strategies are coordinated for optimal results.
Key architectural components include the query analyzer, which breaks down complex queries into manageable sub-queries, and the retrieval critic, which evaluates the quality of retrieved information and decides whether additional retrieval rounds are needed.
Self-Correction Mechanisms
One of the most powerful features of agentic RAG is its ability to self-correct. When initial retrieval results are insufficient or irrelevant, the system can automatically reformulate queries and retry.
This self-correction loop involves evaluating retrieved context against the original query, identifying gaps or mismatches, reformulating the query to address these gaps, and performing additional retrieval rounds. The result is a system that converges on high-quality answers through iterative refinement.
Adaptive Query Strategies
Agentic RAG systems employ adaptive strategies that change based on the type and complexity of the query. For simple factual questions, the system might use direct retrieval. For complex, multi-faceted questions, it might decompose the query into multiple sub-queries and synthesize the results.
This adaptability makes agentic RAG particularly effective for enterprise applications where queries can range from simple lookups to complex analytical questions. The system’s ability to choose the right strategy for each query type ensures consistently high-quality results.
Comparing RAG System Types
When comparing these different types of RAG systems, it’s clear that each has its strengths and ideal use cases.
Traditional RAG remains suitable for straightforward question-answering tasks where the document corpus is well-structured and queries are relatively simple.
HtmlRAG excels when dealing with web-based content where document structure carries important semantic information. It’s particularly valuable for applications that need to preserve the hierarchical organization of web pages.
Multimodal RAG is the choice when information spans multiple modalities. In domains like healthcare, e-commerce, and education where visual and textual information must be considered together, multimodal approaches provide superior results.
Agentic RAG is best suited for complex, enterprise-grade applications where queries are varied and often require multiple retrieval steps. Its self-correcting nature makes it particularly reliable for mission-critical applications.
Future Directions in RAG Development

As we look to the future, RAG systems will continue to evolve. We can expect to see more hybrid approaches that combine the strengths of different RAG types. For instance, an agentic system that can handle multimodal data while preserving HTML structure would represent a significant advancement.
Other emerging trends include real-time RAG systems that can process and retrieve information with minimal latency, personalized RAG that adapts to individual user preferences and history, and federated RAG systems that can retrieve information across distributed data sources while maintaining privacy.
The field of retrieval-augmented generation is rapidly advancing, and these modern types of RAG systems represent just the beginning. As AI continues to evolve, we can expect even more sophisticated approaches to information retrieval and generation.


